Building for Scale from Day One: Architecture Patterns for Production AI Systems
Posted by: Syncloop | April 04, 2026
The typical scaling story goes like this: Build a prototype that works beautifully with 10 users. Launch. Succeed. Hit 1,000 users and things slow down. Hit 10,000 and things break. Spend three months re-architecting while growth stalls.
This story is so common in AI systems that teams treat it as inevitable. It isn't. The re-architecture is usually forced by early decisions that seemed convenient but created scaling limits — limits that could have been avoided with different initial choices.
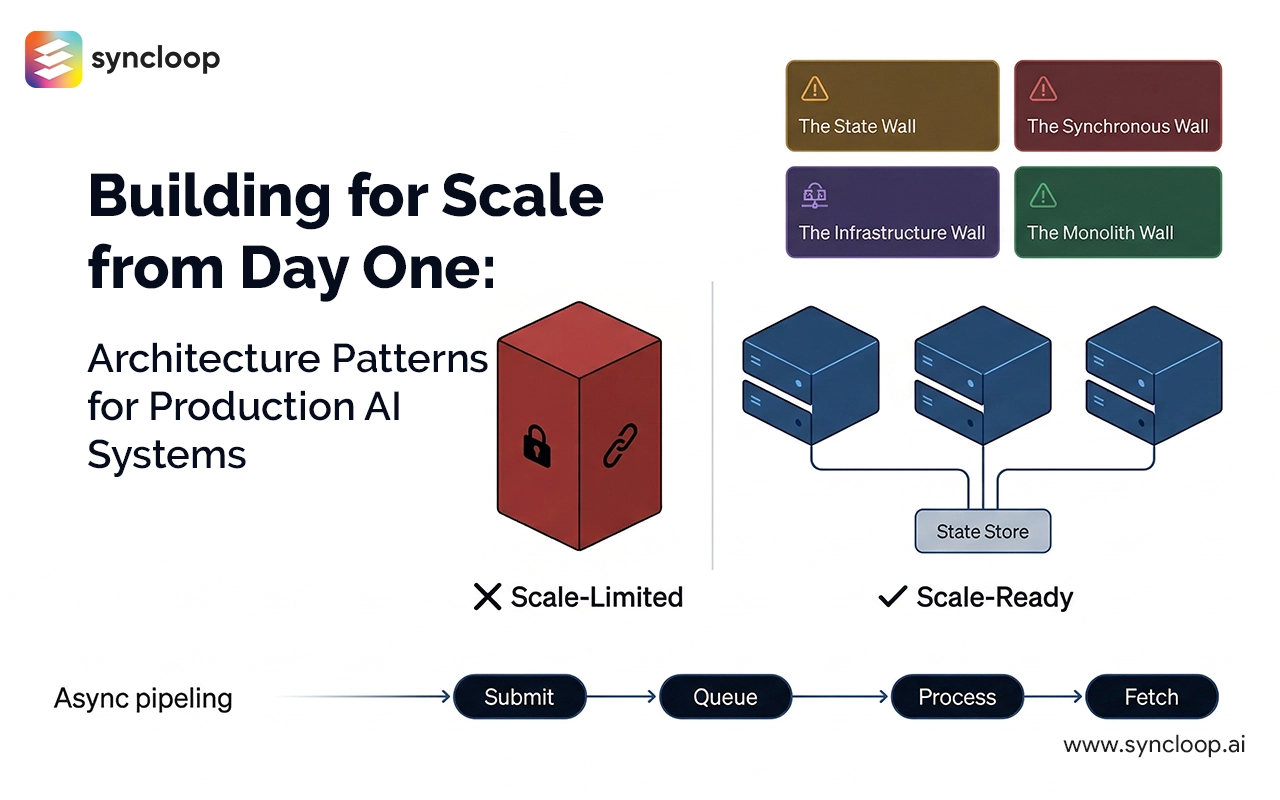
The Scaling Walls
AI systems hit predictable walls as they scale. Understanding these walls helps you avoid building them into your architecture.
Wall 01
The State Wall
Systems that maintain state in single instances can't scale horizontally. Add more servers and they don't share state, creating inconsistent behavior.
Wall 02
The Synchronous Wall
Systems that block while AI models process can only handle as many concurrent requests as they have blocking threads — devastating for multi-step agent workflows.
Wall 03
The Infrastructure Wall
Systems deeply integrated with specific infrastructure can't migrate to better options as requirements change. You're locked into your initial choices indefinitely.
Wall 04
The Monolith Wall
Systems where all components must deploy together become difficult to update or scale selectively. Changes in one area force redeployment of everything.
Stateless architecture enables horizontal scaling. Any instance can handle any request because state lives outside the agent, not inside it.
The Four Scale-Ready Patterns
1
Stateless Agent Design
Individual agent instances hold no state — all state lives in external stores any instance can access. Any instance can handle any request. Instances can be added or removed dynamically. Failures don't lose state because state wasn't in the failed instance.
2
Horizontal Scaling
Add capacity by adding instances rather than making existing ones larger. Requires intelligent workload distribution, auto-scaling triggers, graceful degradation, and zero-downtime deployment — all essential for production AI workloads.
3
Asynchronous Processing
Decouple request submission from result delivery. The caller submits a task and receives a handle. The system processes when resources are available. Critical for multi-step agent workflows and large document processing — synchronous AI doesn't scale.
4
Infrastructure Abstraction
Your agents shouldn't know which cloud they're running on. Separate business logic from deployment details. This enables cloud migration, optimizes infrastructure independently of application changes, and enables infrastructure automation.
Asynchronous processing frees threads immediately after task submission, enabling dramatically higher concurrency for AI workflows.
The Day One Decision
Scale-ready architecture doesn't cost more than scale-limited architecture. The code is similar in complexity. The development time is comparable. The difference is in which patterns you choose. Choose scale-ready patterns from day one, and you avoid the re-architecture tax that trips up so many AI systems.
Choose scale-limited patterns, and you're building a wall you'll eventually have to tear down — usually at the worst possible time, when your system is under load and growth is stalling.
The fear is real. HashiCorp changed Terraform's license. Redis went from open to restricted. MongoDB, Elastic, Confluent—the list of "open-source" platforms that shifted to more restrictive terms keeps growing.