The Hidden Cost of Fragmented AI: What 5-10 Disconnected Libraries Are Costing You
Posted by: Steve Johns | January 16,2026
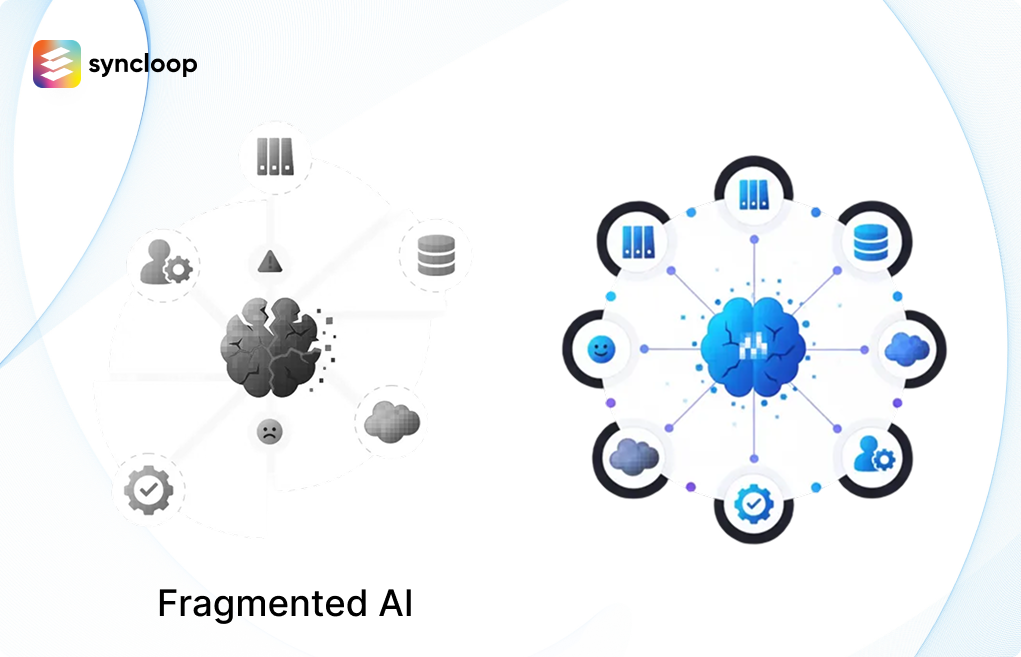
Your AI stack probably includes LangChain, a workflow tool, custom scripts, vector databases, and several point solutions. Here's why that architecture is silently draining your team's productivity.
Open your team's package .json or requirements.txt. Count theAI-related dependencies. Now count the integrations between them. If you're like most engineering organizations building multi-agent systems, you're looking at a dependency graph that would make a distributed systems textbook proud—and not in a good way.
This fragmentation didn't happen by accident. It's the natural result of how the AI ecosystem evolved: each problem spawned a specialized solution, and each solution became another component in an increasingly complex stack.
But the cost of this fragmentation is higher than most teams realize and it's compounding with every new tool you add.
Anatomy of a Fragmented AI Stack
Let's be specific about what fragmentation looks like in practice. A typical multi-agent AI implementation today includes several distinct components:
- LLM Orchestration: LangChain, LlamaIndex, or similar frameworks for managing language model interactions, prompt templates, and chain logic.
- Workflow Automation: n8n, Zapier, or custom orchestration code for handling multi-step processes and system integrations.
- Vector Storage: Pinecone, Weaviate, Qdrant, or Chroma for embedding storage and similarity search.
- Agent Frameworks: CrewAI, AutoGen, or custom implementations for multi-agent coordination.
- Observability: LangSmith, Weights & Biases, or custom logging for monitoring and debugging.
Each of these tools is excellent at its specific job. The problem isn't the individual tools it's what happens when you need them to work together.
The Integration Tax
Here's the cost breakdown that rarely appears in vendor comparisons or technical planning documents:
- Initial Integration (20-30% of project time): Getting five different tools to share data, context, and state requires custom code. Authentication, data format translation, error handling none of this is core to your business logic, but it all consumes engineering hours.
- Ongoing Maintenance (15-20% of AI team bandwidth): Each tool updates on its own schedule. Breaking changes in one dependency can cascade across your stack. Version compatibility becomes a recurring headache.
- Debugging Complexity (exponential with tool count): When something fails in a multi-tool pipeline, tracing the issue across system boundaries is significantly harder than debugging within a single environment. Each tool has its own logging format, its own error taxonomy, its own conceptual model.
- Context Loss at Boundaries: Every time data crosses from one tool to another, context gets serialized, deserialized, and potentially corrupted. State management across tool boundaries is notoriously difficult.
Add these up, and you're looking at 35-40% of your AI team's capacity going to integration work rather than building capabilities that differentiate your business.

The Scaling Cliff
The integration tax is painful but manageable for proof-of-concept projects. The real crisis hits at scaling.
Here's a pattern we see repeatedly: a team builds a successful AI prototype using a collection of best-of-breed tools. The prototype works beautifully in the lab. Then comes the call to move to production, and everything falls apart.
- Performance bottlenecks appear at integration points. The serialization overhead that was negligible at low volume becomes a showstopper at production scale.
- Reliability requirements expose single points of failure. Each tool in the chain becomes a potential outage source. Graceful degradation across tool boundaries is complex to implement correctly.
- Security and compliance audits uncover gaps. When AI decisions need to be explainable and auditable, tracing logic across multiple systems with different data models is often impossible.
The result? Teams find themselves rebuilding from scratch for production essentially paying for the same capability twice. The 18-month timeline for AI deployment that everyone complains about? A significant portion of that is the architectural rewrite required to make fragmented prototypes production-ready.
The Context Engineering Challenge
There's a deeper issue that fragmentation creates, and it's becoming increasingly critical as AI systems grow more sophisticated: context engineering.
Modern AI agents need context to perform well. Not just the immediate user input, but the full picture: what happened in previous interactions, what tools are available, what constraints apply, what other agents are doing. Getting this context to the right agent at the right time is what separates AI systems that feel intelligent from those that feel disjointed.
In a fragmented stack, context engineering becomes nightmarish. Each tool maintains its own state. Sharing context between tools requires explicit passing of data through integration layers—data that may be formatted differently, indexed differently, and interpreted differently by each system.
The result is AI agents that suffer from a kind of organizational amnesia: they can't remember what just happened in a different part of the system, and they can't coordinate effectively with other agents because there's no shared understanding of the current situation.
The Unified Platform Alternative
The alternative to fragmentation is a unified platform approach: a single environment where AI agents, workflows, integrations, and human interactions all operate with shared context and coordinated execution.
The benefits of unification compound across several dimensions:
Zero Integration Tax: When all components are designed to work together from the ground up, there's no serialization overhead, no version compatibility headaches, no custom glue code to maintain.
Consistent Context: All agents operate with shared access to the same state, the same history, the same understanding of what's happening. Coordination becomes natural rather than engineered.
Visual Debugging: When the entire system operates in one environment, you can see the full picture. Trace an issue from input to output without jumping between tools and log formats.
Prototype-to-Production Path: Build once, scale once. The architecture that works for experimentation works for production, eliminating the costly rebuild cycle.
Making the Transition
If your current stack is already fragmented, the transition to unification doesn't have to be all-or-nothing. The key is to identify where integration costs are highest and start consolidating there.
Look for opportunities where you're currently maintaining custom integration code between AI components. Look for projects that stalled at the prototype stage due to production requirements. Look for debugging sessions that require jumping between multiple observability tools.
These are the pressure points where fragmentation costs are most visible—and where unification delivers the fastest returns. The engineering team that recaptures 35-40% of its capacity by eliminating integration overhead isn't just more efficient. It's fundamentally more capable. That reclaimed capacity goes into building features that differentiate your product, not plumbing that simply keeps the lights on.
The tools in your current stack are probably excellent. The question is whether the cost of keeping them connected is worth the capability they provide individually—or whether a unified approach would let your team accomplish more with less architectural overhead.
Back to Blogs