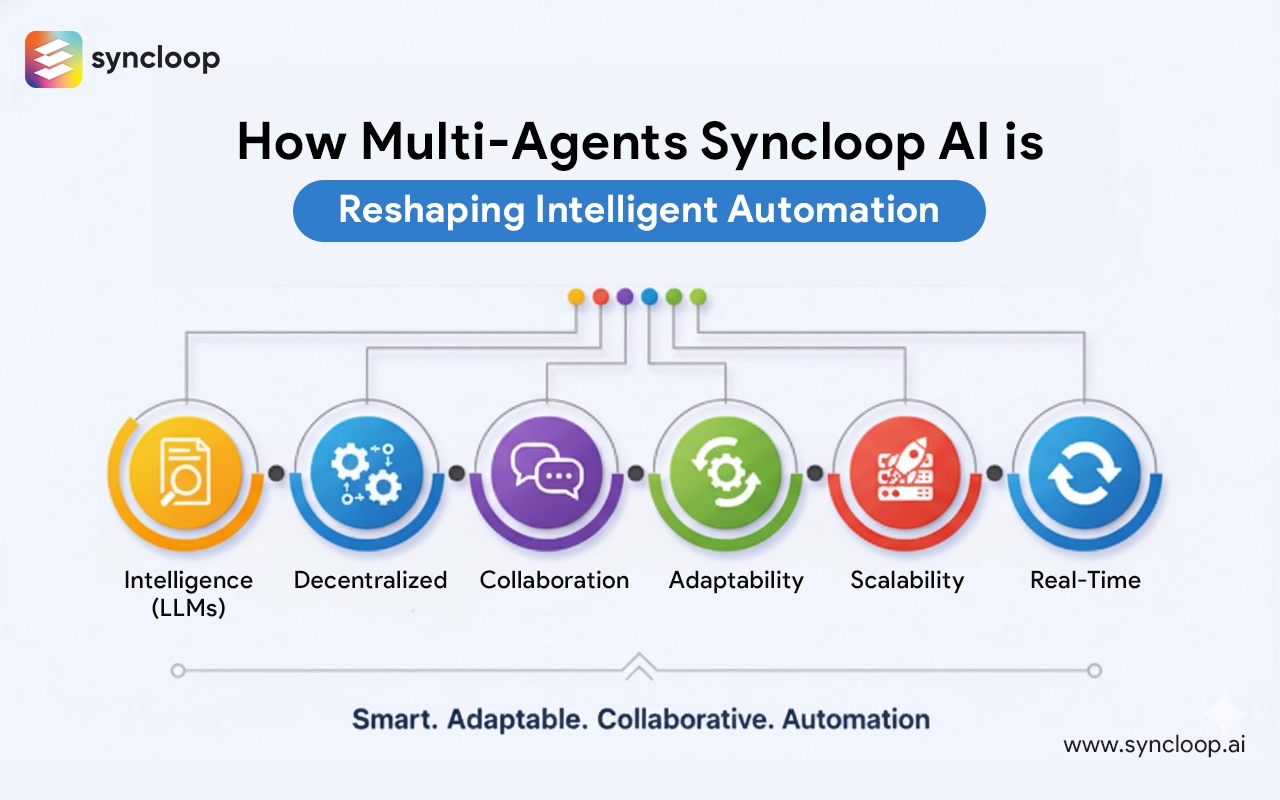
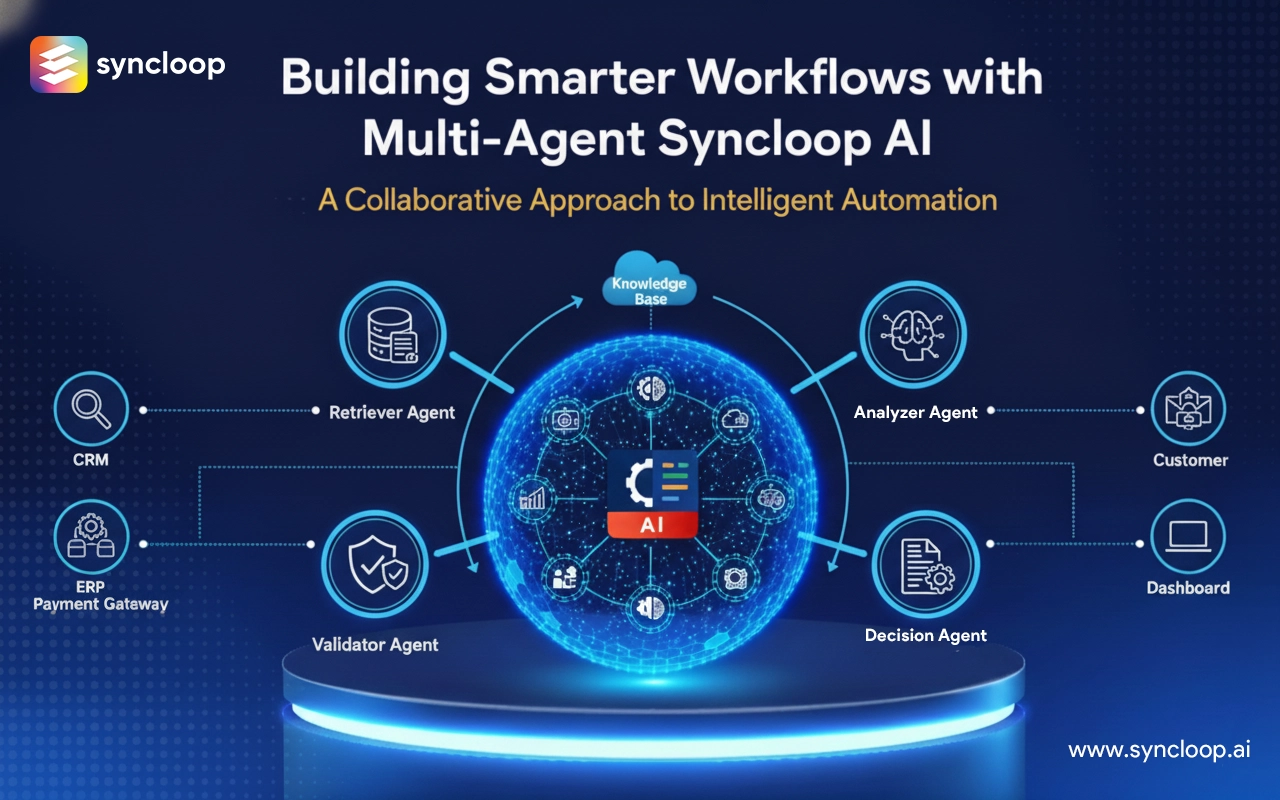
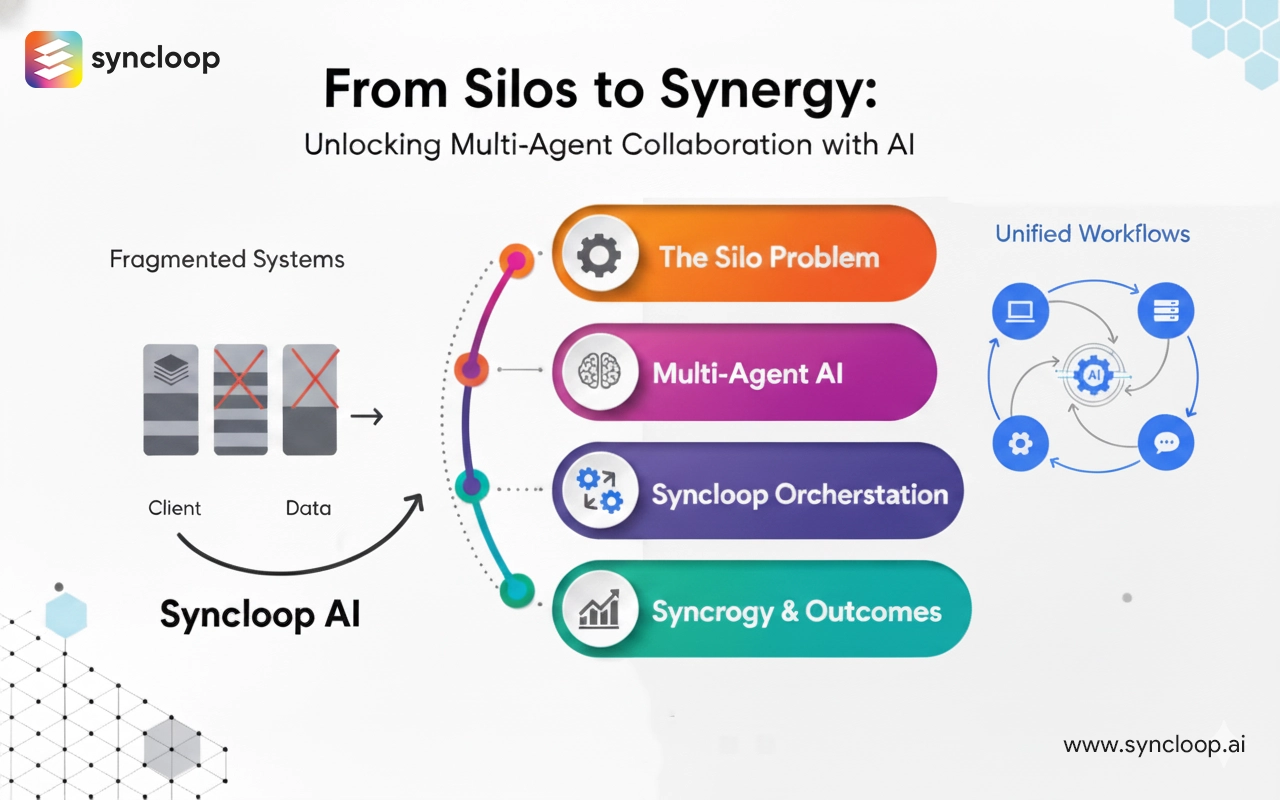
Designing Domain-Specific Agents with Syncloop AI Knowledge Bases
Posted by: Lauren Harris | October 19, 2025
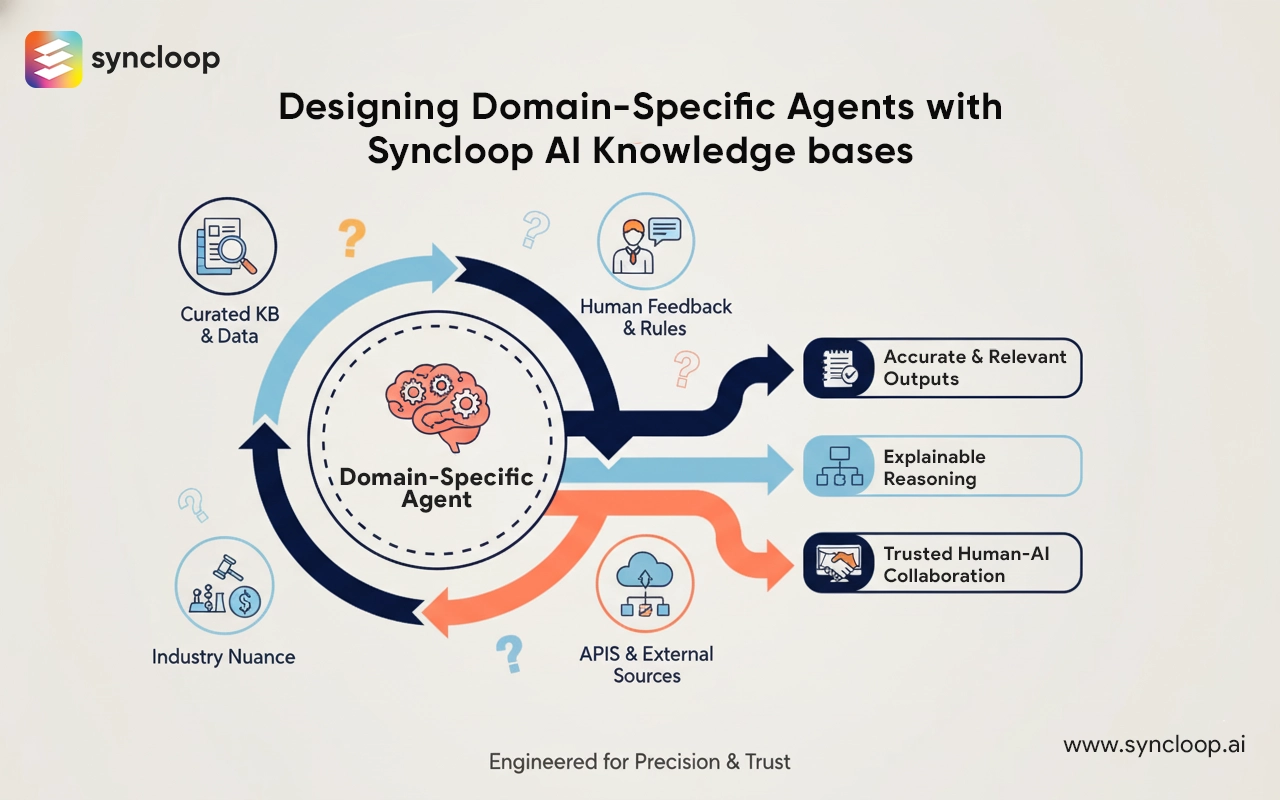
Designing intelligent automation that truly understands a specialized field—healthcare, finance, legal, manufacturing—requires more than generic language models. It requires agents that think in the terms of the domain, surface the right sources, and respect the rules and sensitivities that practitioners expect. Syncloop AI was built for this exact purpose: to combine modular, API-driven agents with curated knowledge bases so organizations can create domain-specific agents that are accurate, explainable, and practical for everyday work.
In this article I’ll walk through the philosophy and practical steps for designing domain-specific agents with Syncloop AI knowledge bases. The emphasis is on purposeful design choices—what to store in knowledge bases, how agents should use that information, and how to preserve trust, compliance, and usefulness. The goal is to help you think of agents as colleagues that augment specialists, not as opaque tools that replace them.
Why domain specificity matters
Generic models can be eloquent and helpful for a broad set of questions, but they frequently miss the nuance that matters in professional settings. A loan decision requires understanding regulatory thresholds; a clinical note needs to reflect medical terminology and privacy constraints; legal research must reference jurisdictional precedents. Domain-specific agents close that gap by grounding generation in curated facts, policies, and data: the knowledge base becomes the agent’s memory and authority.
Making agents domain-aware yields several human-centered benefits:
- Outputs that align with professional language and expectations.
- Fewer risky hallucinations because agents reference vetted sources.
- Faster onboarding for domain teams—agents behave like junior specialists who already know the basics..
- Traceable decisions that can be audited and corrected.
Designing domain-specific agents is therefore about shaping what the agent knows, how it retrieves and uses that knowledge, and how it exposes its reasoning to humans.
Foundations: what belongs in a domain knowledge base
A knowledge base (KB) for a domain is not a dump of everything; it’s a curated, versioned set of artifacts that an agent can consult reliably. Building a high-quality KB starts with defining scope and trust.
- Canonical documents: laws, standards, clinical guidelines, policy manuals, SLAs—anything that defines official rules.
- Operational data: product catalogs, pricing matrices, process diagrams, configuration records that agents use for execution.
- Historical records: incident logs, prior decisions, annotated examples that help the agent learn patterns.
- Terminology and ontologies: glossaries, taxonomies, and relationship maps that help disambiguate domain language.
- Approved templates and responses: standardized text for compliance-sensitive outputs (reports, notices, disclaimers).
- Trusted external sources and feeds: APIs or vetted web resources for data that must be live (e.g., market prices, drug formularies).
Curate content with quality controls: source attribution, version stamps, and owners who are accountable for updates. Treat the KB as a living artifact: it must be maintained, pruned, and audited.
Architecting the agent–KB interaction
Good design separates roles: retrieval, reasoning, validation, and orchestration. That modularity is central to Syncloop AI’s approach.
A typical interaction pattern:
Architecting the agent–KB interaction
Good design separates roles: retrieval, reasoning, validation, and orchestration. That modularity is central to Syncloop AI’s approach.
- A Contextualizer agent interprets the incoming query, identifies intent, and constructs effective retrieval queries (including filters like jurisdiction, date ranges, or product lines).
- Retriever agents query the KB (vector indexes for unstructured text, SQL/Graph queries for structured stores) and return ranked evidence snippets with provenance metadata.
- The Reasoner/Generator agent synthesizes an answer using the retrieved evidence and domain-aware prompts that enforce tone and rules.
- A Verifier agent cross-checks the generated output against canonical rules or additional KB slices and flags inconsistencies
- An Orchestrator agent manages workflow steps, deciding whether to escalate to a human reviewer or to perform an automated action.
Each step should produce traceable artifacts: the retrieval hits, the prompts used, the intermediate reasoning pieces, and the final decision. That traceability is what converts outputs into defensible actions.
Design principles for domain prompts and instruction
How you ask an agent to use knowledge matters. Domain prompts should be explicit about authority, constraints, and desired format.
Principles:
- Always include source context: instruct the agent to prefer “KB sources labeled as authoritative” and to cite them.
- Define failure modes: tell the agent what to do if evidence is missing—ask for clarification, provide a tentative answer with caveats, or route to a human.
- Enforce compliance briefings: embed regulatory or policy constraints in prompts (e.g., “Do not provide clinical recommendations beyond triage; escalate when X conditions are present”).
- Use templates for structured outputs: enforce formats for reports, legal memos, or incident summaries so downstream systems can consume them reliably.
- Encourage conservative answers in high-risk areas: favor “I don’t know” or “requires human review” when confidence is low.
Syncloop AI’s agent architecture lets you maintain these prompt templates as part of the KB, so they evolve alongside policy updates.
Managing provenance and explainability
Domain teams demand to know why an agent said what it did. Attach provenance metadata to every retrieval and generation result:
- Source identifier (document name, version, or external API endpoint).
- Retrieval score and why the snippet was selected.
- Prompt and reasoning steps used for generation.
- Confidence or validation flags from the Verifier agent.
Present this information in human-friendly ways: a short answer plus an expandable “why” section that lists the cited sources and the chain of logic. That transparency builds trust and accelerates adoption among domain experts.
Quality assurance: testing and continuous improvement
Designing domain-specific agents is iterative. Use a lifecycle approach:
- Seed the KB with authoritative content and craft representative prompts.
- Run simulation tests with curated test cases, including edge cases and adversarial inputs.
- Measure not only accuracy but also appropriateness, compliance, and human review rates.
- Collect human feedback: every correction should be logged and fed back into the KB or into prompt adjustments.
- Use A/B testing where different prompt or retrieval strategies are compared on live traffic.
Syncloop AI supports parallel agent instances and staged rollouts so you can test at scale without affecting production operations.
Operational practices: governance, ownership, and lifecycle
A reliable domain agent requires clear governance:
- Assign owners for each KB slice—subject-matter experts who approve updates.
- Maintain versioning and an approval workflow for KB changes, with audit trails.
- Set retention and archival policies for outdated content; sometimes older guidance must be preserved as historical context but not actively used.
- Define escalation thresholds for human review depending on risk (e.g., monetary thresholds, legal exposure).
- Include regular security reviews of KB access controls and ensure agents only access what they’re authorized to.
These practices prevent drift, maintain quality, and ensure compliance across the agent lifetime
Human-in-the-loop: where people matter most
Domain agents should enhance, not replace, human expertise. Build interaction patterns that keep humans in meaningful control:
- Allow reviewers to annotate KB entries with clarifications or errata that are immediately visible to agents.
- Provide simple correction interfaces: when an agent is wrong, a reviewer should be able to correct the answer and optionally add the correction to the KB.
- Offer clear override controls and explain the consequences of actions so humans can make informed decisions.
When agents and humans operate as a team, the system becomes more reliable and humane
Scaling domain agents without losing fidelity
When expanding from a single domain to many, maintain fidelity by:
- Reusing shared retrieval and governance components while isolating domain KBs to prevent cross-contamination.
- Creating domain templates for prompts and verification rules so each new agent starts from a proven configuration.
- Monitoring cross-domain drift: watch for cases where one domain’s language or policy leaks into another’s outputs.
- Investing in tooling that makes it easy for domain experts to update KBs without engineering intervention
Syncloop AI’s modularity and API-led design make scaling practical: you add KBs and agent instances, not technical debt.
Conclusion
Designing domain-specific agents with Syncloop AI knowledge bases is a deliberate act of engineering and curation. It’s about deciding what an agent should know, how it should use that knowledge, and how it should expose its reasoning so humans can trust and collaborate with it. When knowledge bases are curated, provenance is preserved, prompts are crafted to enforce domain rules, and governance ties people to the lifecycle, agents become reliable collaborators—accelerating work while protecting the values and constraints of the domain.
The result is not merely smarter automation; it’s automation that behaves like a thoughtful colleague—grounded in trusted information, transparent in its decisions, and designed to amplify human expertise. That is the promise of domain-specific agents built on Syncloop AI.
Back to Blogs